
|
SVP Technology at Fiserv; large scale system architecture/infrastructure, tech geek, reading, learning, hiking, GeoCaching, ham radio, married, kids
|


A long long time ago, BGP implementations would use a Maximum Segment Size (MSS) of 536 bytes for BGP peerings. Why 536? Because in RFC 791, the original IP RFC, the maximum length of a datagram is defined as follows:
Total Length: 16 bits
Total Length is the length of the datagram, measured in octets,
including internet header and data. This field allows the length of
a datagram to be up to 65,535 octets. Such long datagrams are
impractical for most hosts and networks. All hosts must be prepared
to accept datagrams of up to 576 octets (whether they arrive whole
or in fragments). It is recommended that hosts only send datagrams
larger than 576 octets if they have assurance that the destination
is prepared to accept the larger datagrams.
The number 576 is selected to allow a reasonable sized data block to
be transmitted in addition to the required header information. For
example, this size allows a data block of 512 octets plus 64 header
octets to fit in a datagram. The maximal internet header is 60
octets, and a typical internet header is 20 octets, allowing a
margin for headers of higher level protocols.
The idea was to allow for 512 octets of data plus headers. Because the IP header and TCP header, without options, are 20 bytes, respectively, that means MSS would be 576-40 = 536 bytes.
Now, one could argue that because BGP uses TCP as transport, and that the MSS is advertised (not negotiated), then it would be safe to use a higher value. However, that makes the assumption that the path between the peers can support it. The safe assumption was to only assume the minimal that was required according to the standard, 576 bytes of IP datagrams.
The drawback of using a MSS of 536 bytes is that it’s not very efficient. Most networks support an MTU of at least 1500 bytes. Without any IP or TCP options, that leaves an MSS of 1460 bytes. Using only 536 bytes would mean that we are only operating at roughly 37% efficiency (536/1460). This was perhaps acceptable when the number of prefixes were low, but now you’ll typically see a million prefixes in the Default Free Zone (DFZ) and millions of routes in MPLS VPN networks. Only using 536 bytes would lead to convergence issues as having to send many updates to cover all the Network Layer Reachability Information (NLRI).
What do we do to become more efficient? There is a well-known mechanism called Path MTU Discovery (PMTUD). With PMTUD, we send as large datagrams as we can and rely on that devices not supporting the size of the datagram, responds back with ICMP packet, specifically Type 3 Code 4 – Fragmentation needed (for IPv4), informing us to send a smaller datagram. This works well as long as the ICMP packets can be received.
BGP implementations today typically use PMTUD to define the MSS when establishing a peering. Inspecting a BGP neighbor on IOS-XE gives us information on PMTUD and MSS:
BGP1#show bgp ipv4 uni nei 172.16.0.18 Transport(tcp) path-mtu-discovery is enabled Datagrams (max data segment is 1460 bytes): Peer MSS: 1460
Here, a MSS of 1460 bytes was selected based on the the TCP 3-way handshake. Let’s look at it in more detail using debugs and packet captures. Here is a debug of 172.16.0.2 establishing a peer with 172.16.0.18:
TCP: pmtu enabled,mss is now set to 1460 TCP: sending SYN, seq 3241166397, ack 0 TCP0: Connection to 172.16.0.18:179, advertising MSS 1460
Let’s review the initial SYN in Wireshark as well:
Frame 43: 66 bytes on wire (528 bits), 66 bytes captured (528 bits)
Ethernet II, Src: 52:54:00:b6:c6:15, Dst: 52:54:00:11:04:23
Internet Protocol Version 4, Src: 172.16.0.2, Dst: 172.16.0.18
0100 .... = Version: 4
.... 0101 = Header Length: 20 bytes (5)
Differentiated Services Field: 0xc0 (DSCP: CS6, ECN: Not-ECT)
Total Length: 52
Identification: 0x4818 (18456)
010. .... = Flags: 0x2, Don't fragment
...0 0000 0000 0000 = Fragment Offset: 0
Time to Live: 3
Protocol: TCP (6)
Header Checksum: 0xd6b7 [validation disabled]
[Header checksum status: Unverified]
Source Address: 172.16.0.2
Destination Address: 172.16.0.18
[Stream index: 0]
Transmission Control Protocol, Src Port: 28636, Dst Port: 179, Seq: 0, Len: 0
Source Port: 28636
Destination Port: 179
[Stream index: 13]
[Stream Packet Number: 1]
[Conversation completeness: Incomplete, DATA (15)]
[TCP Segment Len: 0]
Sequence Number: 0 (relative sequence number)
Sequence Number (raw): 3241166397
[Next Sequence Number: 1 (relative sequence number)]
Acknowledgment Number: 0
Acknowledgment number (raw): 0
1000 .... = Header Length: 32 bytes (8)
Flags: 0x002 (SYN)
Window: 16384
[Calculated window size: 16384]
Checksum: 0x5fe6 [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
Options: (12 bytes), Maximum segment size, SACK permitted, No-Operation (NOP), No-Operation (NOP), Window scale, End of Option List (EOL)
TCP Option - Maximum segment size: 1460 bytes
TCP Option - SACK permitted
TCP Option - No-Operation (NOP)
TCP Option - No-Operation (NOP)
TCP Option - Window scale: 0 (multiply by 1)
TCP Option - End of Option List (EOL)
[Timestamps]
Note that the Don’t Fragment (DF) bit is set in the IP datagram and that the MSS is 1460 bytes in the TCP segment. Having DF set helps with PMTUD.
Establishing a BGP peer is rarely a problem from the perspective of the MTU of the path. This is because the TCP 3-way handshake, BGP OPEN, and KEEPALIVEs are all typically small:
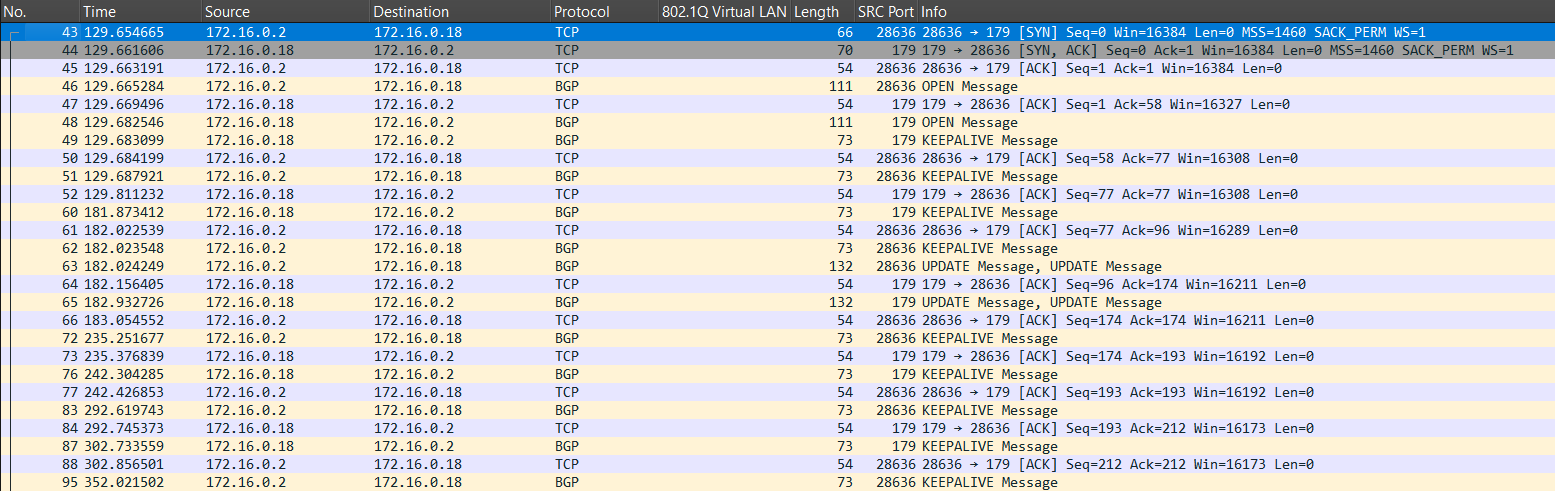
In the image above, also the UPDATEs were small, because I was only advertising a limited number of prefixes. It’s the UPDATEs that will be large if there are many prefixes to advertise.
Once the peering has been established, we want to verify the liveness of it. This is done by receiving KEEPALIVEs or UPDATEs. UPDATES are only sent when something changed, so we typically rely on KEEPALIVEs to verify liveness. Understand that also UPDATEs reset the keepalive timer, though. This process is shown below:
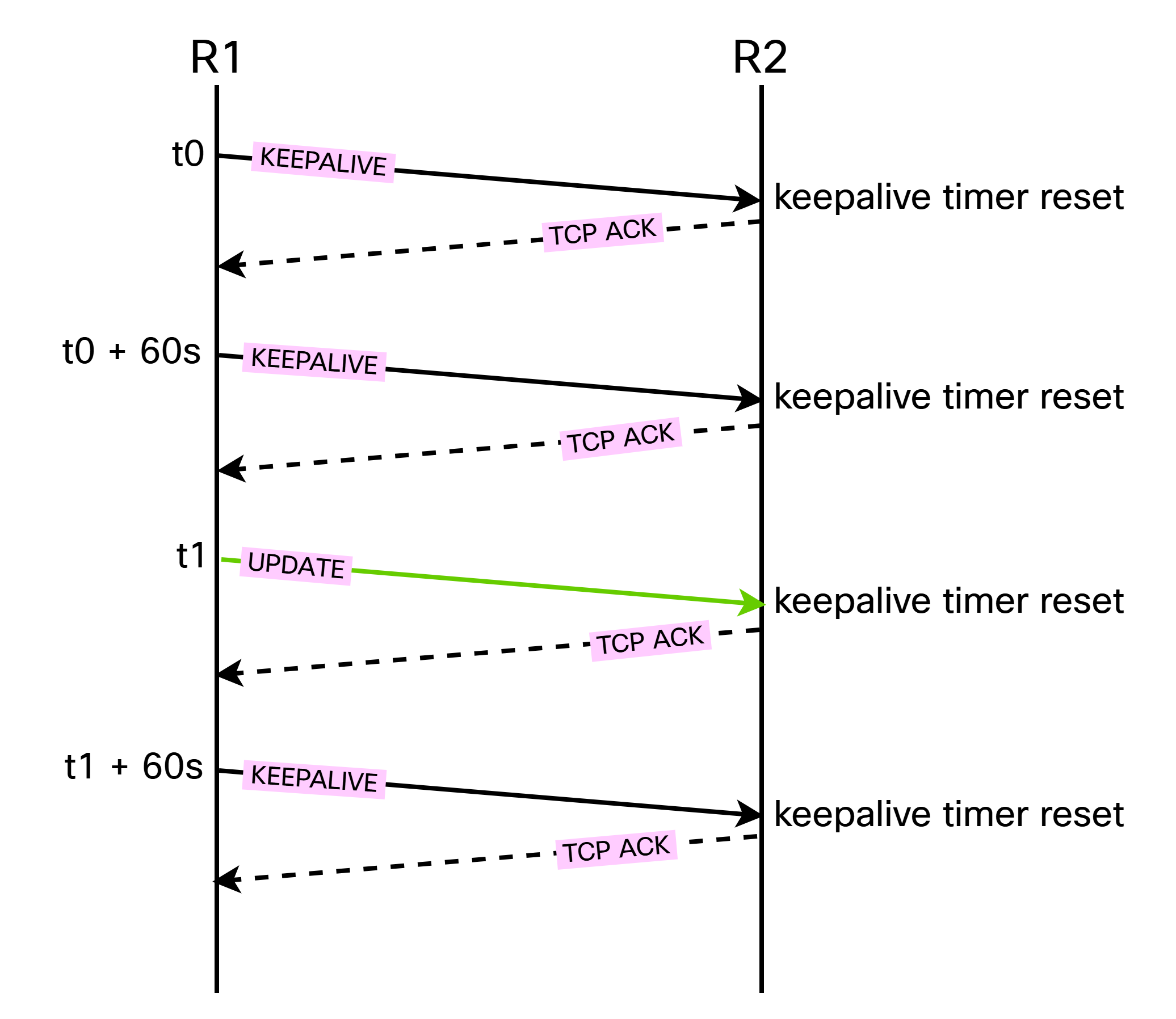
Note that the KEEPALIVEs were sent 60 seconds apart, but at t1 an UPDATE was sent so the next KEEPALIVE will be sent at t1 + 60 seconds. Also the UPDATE is resetting the keepalive timer. Every segment, since it’s TCP, will be ACKed. Below is an example of a KEEPALIVE:
Frame 51: 73 bytes on wire (584 bits), 73 bytes captured (584 bits)
Ethernet II, Src: 52:54:00:b6:c6:15, Dst: 52:54:00:11:04:23
Internet Protocol Version 4, Src: 172.16.0.2, Dst: 172.16.0.18
Transmission Control Protocol, Src Port: 28636, Dst Port: 179, Seq: 58, Ack: 77, Len: 19
Source Port: 28636
Destination Port: 179
[Stream index: 13]
[Stream Packet Number: 9]
[Conversation completeness: Incomplete, DATA (15)]
[TCP Segment Len: 19]
Sequence Number: 58 (relative sequence number)
Sequence Number (raw): 3241166455
[Next Sequence Number: 77 (relative sequence number)]
Acknowledgment Number: 77 (relative ack number)
Acknowledgment number (raw): 3598427241
0101 .... = Header Length: 20 bytes (5)
Flags: 0x018 (PSH, ACK)
Window: 16308
[Calculated window size: 16308]
[Window size scaling factor: 1]
Checksum: 0x20a1 [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
[Timestamps]
[SEQ/ACK analysis]
TCP payload (19 bytes)
[PDU Size: 19]
Border Gateway Protocol - KEEPALIVE Message
It is then ACKed (notice the sequence number of 77):
Frame 52: 54 bytes on wire (432 bits), 54 bytes captured (432 bits)
Ethernet II, Src: 52:54:00:11:04:23, Dst: 52:54:00:b6:c6:15
Internet Protocol Version 4, Src: 172.16.0.18, Dst: 172.16.0.2
Transmission Control Protocol, Src Port: 179, Dst Port: 28636, Seq: 77, Ack: 77, Len: 0
Source Port: 179
Destination Port: 28636
[Stream index: 13]
[Stream Packet Number: 10]
[Conversation completeness: Incomplete, DATA (15)]
[TCP Segment Len: 0]
Sequence Number: 77 (relative sequence number)
Sequence Number (raw): 3598427241
[Next Sequence Number: 77 (relative sequence number)]
Acknowledgment Number: 77 (relative ack number)
Acknowledgment number (raw): 3241166474
0101 .... = Header Length: 20 bytes (5)
Flags: 0x010 (ACK)
Window: 16308
[Calculated window size: 16308]
[Window size scaling factor: 1]
Checksum: 0x24bc [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
[Timestamps]
[SEQ/ACK analysis]
With a small amount of prefixes, we’re not going to have any issues. I updated my configuration in the lab to advertise roughly 500 prefixes. Now we’re going to see how BGP behaves in different scenarios.
First, let’s see PMTUD in action. I lowered the MTU between my peers to 1400 bytes. Now let’s see what happens:
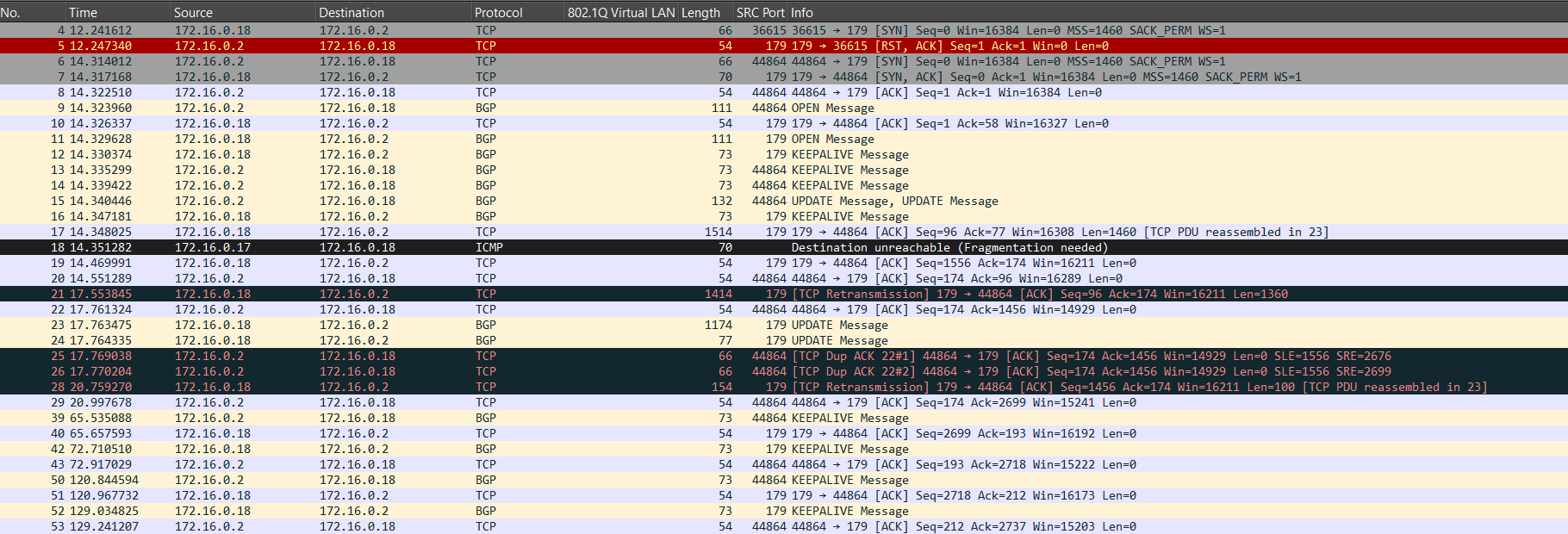
Notice that 172.16.0.18 sent an UPDATE that was 1514 bytes. That segment can’t make it since there’s now an MTU of 1400 bytes. We receive Fragmentation needed, informing us of 1400-byte MTU:
Frame 18: 70 bytes on wire (560 bits), 70 bytes captured (560 bits)
Ethernet II, Src: 52:54:00:30:34:eb, Dst: 52:54:00:a3:18:f8
Internet Protocol Version 4, Src: 172.16.0.17, Dst: 172.16.0.18
Internet Control Message Protocol
Type: 3 (Destination unreachable)
Code: 4 (Fragmentation needed)
Checksum: 0x79ec [correct]
[Checksum Status: Good]
Unused: 0000
MTU of next hop: 1400
Internet Protocol Version 4, Src: 172.16.0.18, Dst: 172.16.0.2
Transmission Control Protocol, Src Port: 179, Dst Port: 44864
The segment is resent with 1360 bytes of data:
Frame 21: 1414 bytes on wire (11312 bits), 1414 bytes captured (11312 bits)
Ethernet II, Src: 52:54:00:a3:18:f8, Dst: 52:54:00:30:34:eb
Internet Protocol Version 4, Src: 172.16.0.18, Dst: 172.16.0.2
Transmission Control Protocol, Src Port: 179, Dst Port: 44864, Seq: 96, Ack: 174, Len: 1360
Source Port: 179
Destination Port: 44864
[Stream index: 1]
[Stream Packet Number: 15]
[Conversation completeness: Incomplete, DATA (15)]
[TCP Segment Len: 1360]
Sequence Number: 96 (relative sequence number)
Sequence Number (raw): 1786143533
[Next Sequence Number: 1456 (relative sequence number)]
Acknowledgment Number: 174 (relative ack number)
Acknowledgment number (raw): 3756764660
0101 .... = Header Length: 20 bytes (5)
Flags: 0x010 (ACK)
Window: 16211
[Calculated window size: 16211]
[Window size scaling factor: 1]
Checksum: 0xa5ac [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
[Timestamps]
[SEQ/ACK analysis]
TCP payload (1360 bytes)
Retransmitted TCP segment data (1360 bytes)
Inspecting the BGP peer will now show a datagram size of 1360 bytes, even though peer advertised a MSS of 1460 bytes:
Datagrams (max data segment is 1360 bytes):
The debugs also show this taking place:
ICMP: dst (172.16.0.18) frag. needed and DF set unreachable rcv from 172.16.0.17 mtu:1400 TCP0: ICMP datagram too big received (1400), MSS changes from 1460 to 1360
With this, we can react to changes to the MTU of the path.
The process is also shown in this diagram:
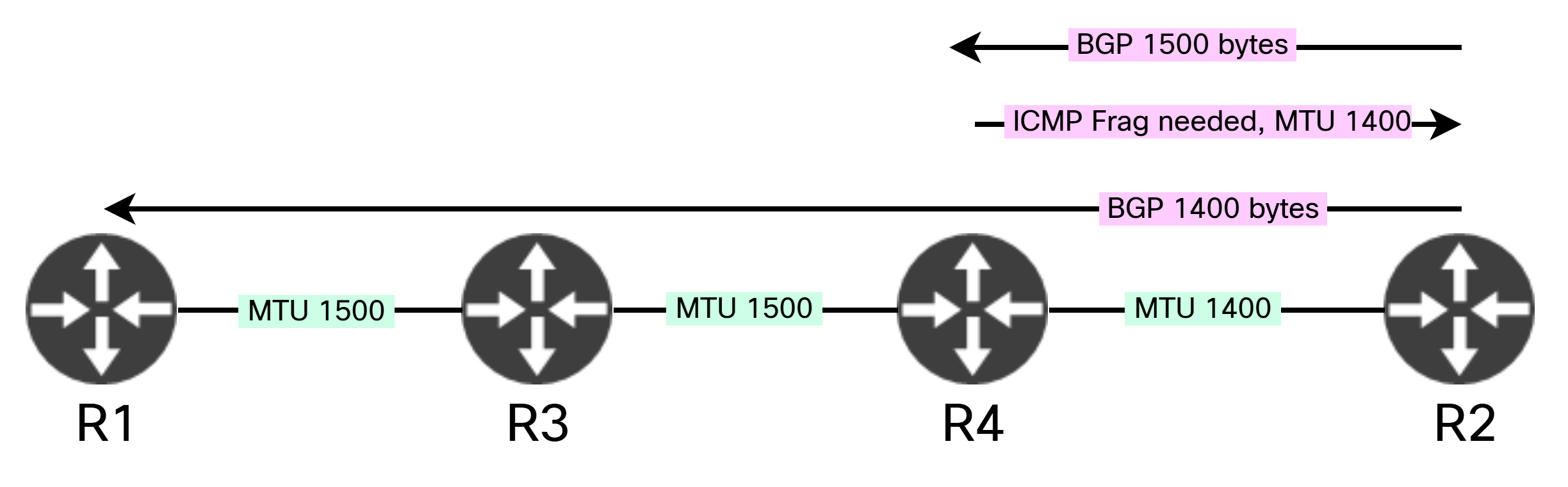
Discovery works well as long as we can receive ICMP messages. This might not always be the case. For example, ICMP unreachables could be disabled, they could be filtered, there are mechanisms like control plane policing, there could be MPLS involved complicating sending unreachables back to originator, and so on. There could also be devices on our path that don’t operate at layer three. For example, what if R3 and R4 were replaced by a switch:

Because the switch is operating at layer two, it has no means of sending ICMP unreachables towards the routers. It would simply drop frames that are too large and we would have an MTU blackhole. Let’s review a scenario like this from BGP’s perspective.
Viewing this in Wireshark shows a nice summary of what’s happening:
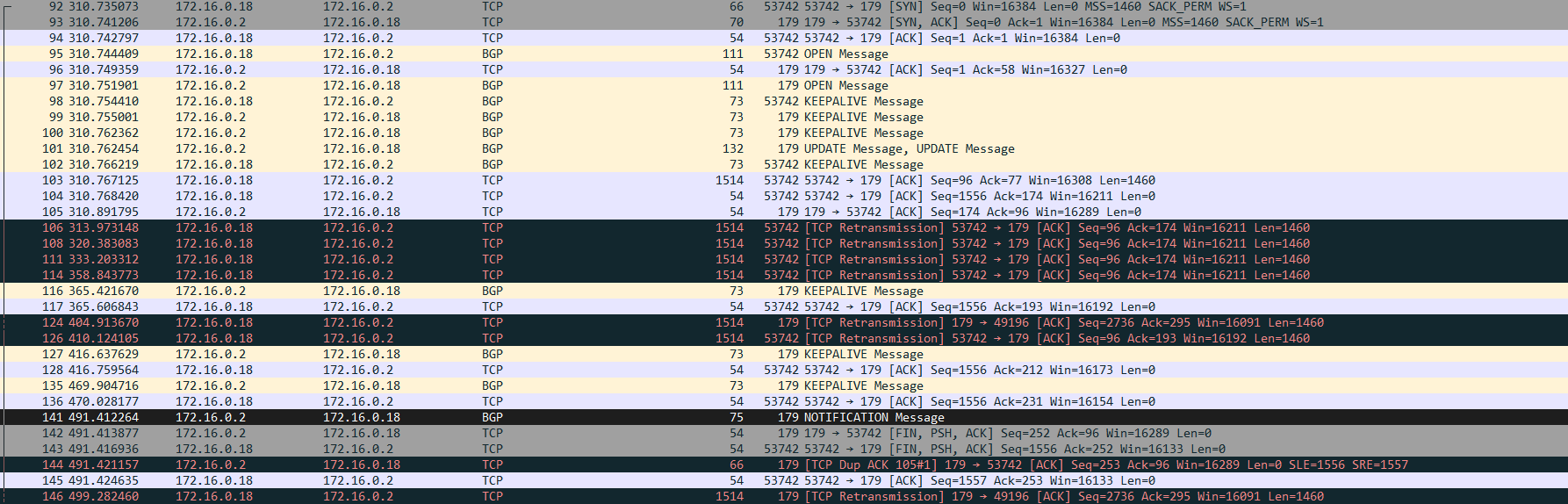
The peering comes up fine as expected. The problem starts when 172.16.0.18 is sending frame 103, which is 1514 bytes. It doesn’t make it, so it retransmits. Because 172.16.0.2 is not receiving any UPDATES or KEEPALIVES, its hold timer will expire and the peering is closed. The diagram below shows what is happening:
Note that KEEPALIVES should be sent every 60 seconds, but there is some discrepancy here, probably due to some jitter in the timer. Also note that the TCP retransmissions back off with longer time between each retransmission. It seems it’s roughly doubling the amount of time between each attempt. As R2 has received neither KEEPALIVEs or UPDATEs from R1, it terminates the peering.
A key point here is that due to behavior of TCP, no KEEPALIVES can make it from R1 as they are stuck behind the UPDATEs that are being retransmitted. Even if we were generating KEEPALIVES, though, that would be a dangerous state to be in as there would be a peering where no, or only some, UPDATES can be received by the peer. It’s better to have a cleaner failure.
Debugs will show the reaction of TCP:
14:23:17.525: TCP0: RETRANS timer expired for TCB 0x7B015617A700 14:23:17.525: 172.16.0.18:179 <---> 172.16.0.2:13807 congestion window changes 14:23:17.525: cwnd from 1556 to 1460, ssthresh from 65535 to 2920 14:23:17.525: tcp0: R ESTAB 172.16.0.2:13807 172.16.0.18:179 seq 2754742286 DATA 1460 ACK 3933720073 WIN 16211 14:23:17.527: TCP0: timeout #1 - timeout is 6410 ms, seq 2754742286 14:23:17.527: TCP: (179) -> 172.16.0.2(13807) 14:23:23.936: TCP0: RETRANS timer expired for TCB 0x7B015617A700 14:23:23.936: tcp0: R ESTAB 172.16.0.2:13807 172.16.0.18:179 seq 2754742286 DATA 1460 ACK 3933720073 WIN 16211 14:23:23.937: TCP0: timeout #2 - timeout is 12820 ms, seq 2754742286 14:23:23.937: TCP: (179) -> 172.16.0.2(13807) 14:23:36.757: TCP0: RETRANS timer expired for TCB 0x7B015617A700 14:23:36.757: tcp0: R ESTAB 172.16.0.2:13807 172.16.0.18:179 seq 2754742286 DATA 1460 ACK 3933720073 WIN 16211 14:23:36.759: TCP0: timeout #3 - timeout is 25640 ms, seq 2754742286 14:23:36.759: TCP: (179) -> 172.16.0.2(13807) 14:24:02.426: TCP0: RETRANS timer expired for TCB 0x7B015617A700 14:24:02.426: tcp0: R ESTAB 172.16.0.2:13807 172.16.0.18:179 seq 2754742286 DATA 1460 ACK 3933720073 WIN 16211 14:24:02.427: TCP0: timeout #4 - timeout is 51280 ms, seq 2754742286 14:24:02.427: TCP: (179) -> 172.16.0.2(13807) 14:24:53.706: TCP0: RETRANS timer expired for TCB 0x7B015617A700 14:24:53.706: tcp0: R ESTAB 172.16.0.2:13807 172.16.0.18:179 seq 2754742286 DATA 1460 ACK 3933720092 WIN 16192 14:24:53.707: TCP0: timeout #5 - timeout is 102560 ms, seq 2754742286 14:24:53.707: TCP: (179) -> 172.16.0.2(13807) 14:24:56.853: TCP0: ACK timer expired for TCB 0x7B015617A700 14:25:55.235: TCP0: ACK timer expired for TCB 0x7B015617A700 14:26:14.576: %BGP-3-NOTIFICATION: received from neighbor 172.16.0.2 4/0 (hold time expired) 0 bytes 14:26:14.576: %BGP-5-NBR_RESET: Neighbor 172.16.0.2 reset (BGP Notification received) 14:26:14.577: TCB7B015617A700 setting property TCP_SSO_TYPE (27) 7B0155D75320 14:26:14.577: TCP: SSO already disabled for 7B015617A700 14:26:14.577: BGP: 172.16.0.2 reset due to BGP Notification received
When viewing stats for the peer, you may see output like the one below:
Keepalives are temporarily in throttle due to closed TCP window Enqueued packets for retransmit: 1, input: 0 mis-ordered: 0 (0 bytes) Sent: 7 (retransmit: 3, fastretransmit: 0, partialack: 0, Second Congestion: 0), with data: 4, total data bytes: 1555
Notice that it says that KEEPALIVES are throttled due to TCP. It also shows that there are packets that need to be retransmitted and have been retransmitted.
One interesting aspect of this scenario is that a session could be alive and well for a long time before it fails. How come? It depends on what UPDATES are sent. For example, the UPDATES could grow in size over time as more prefixes are added. Triggering a ROUTE REFRESH could also potentially reset the peering as that triggers UPDATES being sent.
What can we do when we find us in a scenario where we can’t rely on ICMP unreachables and we can’t or don’t want to adjust the MTU? Normally, we could use something like ip tcp adjust-mss, but that doesn’t generally affect packets generated by the control plane. Instead, we must adjust the MSS of all the TCP segments on the device by using the ip tcp mss command:
R1(config)#ip tcp mss 1200 TCP INFO: TCP is configured for enhanced throughput. It is recommended to set the MSS to a minimum of 1460.
After enabling this, a MSS of 1200 is sent:
14:34:37.628: TCP0: Connection to 172.16.0.18:179, advertising MSS 1200
The other side sees the MSS as 1200 as well:
14:34:37.631: TCP: tcb 7B015617A700 connection to 172.16.0.2:36296, peer MSS 1200, MSS is 516
The BGP peer output shows it also:
Datagrams (max data segment is 1200 bytes): Peer MSS: 1200
With the MSS now being lower than the MTU of the path, UPDATES make it to the peer.
What did we learn?
Many BGP implementations rely on PMTUD to find the MTU of the path. This works well as long as the ICMP unreachables make it without being filtered. There are scenarios where this won’t help as there could be a lower MTU on a device that is not operating at layer three. For such a scenario, you can adjust the MSS of the locally generated TCP segments.
I thought I’ve seen it all, but the networking vendors (and their lack of testing) never cease to amaze me. Today’s special: ArubaCX software VXLAN implementation.
We decided it’s a good idea to rewrite the VXLAN integration tests to use one target device and one FRR container to test inter-vendor VXLAN interoperability. After all, what could possibly go wrong with a simple encapsulation format that could be described on a single page?
Everything worked fine (as expected), except for the ArubaCX VM (running release Virtual.10.15.1005, build ID AOS-CX:Virtual.10.15.1005:9d92f5caa6b6:202502181604), which failed every single test.

Read more of this story at Slashdot.
Sean Goedecke published an interesting compilation of practical advice for engineers. Not surprisingly, they include things like “focus on fundamentals” and “spend your working time doing things that are valuable to the company and your career” (OMG, does that really have to be said?).
Bonus point: a link to an article by Patrick McKenzie (of the Bits About Money fame) explaining why you SHOULD NOT call yourself a programmer (there goes the everyone should be a programmer gospel 😜).